多模态深度学习
多模态深度学习网络学习
开始日期:2026-01-12
当前目标阶段:入门->科研->多模态大模型->项目
学习材料主线:文档->论文->项目
备注:记录要尽量“可复现”,包含版本、超参、数据集、链接与结论
多模态
多模态是多种模态进行处理分析
多任务是多个模型同时执行多个任务
跨模态是指一个模态中学习到的知识应用在另一个模态的数据上
- 跨模态是一种多模态深度学习方法
- 多模态深度学习模型方法:
- 翻译:模式之间的映射关系
- 对齐:模态子元素之间的直接关系
- 融合:结合多个模态数据进行预测
- 协同学习:一种模型中学习到的帮助不同模态上训练的计算模型
- 表征:利用多模态之间的互补性来总结多模态数据
- 多模态深度学习的五个挑战:模态表示、模态传译、模态对齐、模态融合
语句模态的表示方法(word-embedding)
单词模态的独热表示(one-hot)
低维空间表示:独热表示的线性变换
词袋模型:只考虑每个词的出现频率,将频率作为特征地图,不考虑文字的顺序和语法结果
- n-gram:可以捕捉语义结构和上下文信息,维度会 迅速增长。将短语或者一个句子视为一个词袋再统计次数,n表示构成词袋的单词个数,对于每个句子按照n个单词对句子进行拆分。bigarm表示n=2,trigram表示n=3。
- TF-IDF:评估词语对文档中的重要性。如果某个词语在一篇文档中频繁出现,但在其他文档中很少出现,则认为这个词语具有很好的类别区分能力,对文档的区分度高,因此应该给予更高的权重。
TF(词频)表示词语在文档中出现的频率,等于某个词在文档中出现的次数除以总词汇数字。
IDF(逆文档频率)如果一个某个词在很多文档中出现,IDF的值会减小,从而减低值的权重
最终得到的值是TF与IDF相乘
文档词项矩阵(Document-Term Matrix):统计每个词语在每个文档中出现的次数。(既有词频又考虑了不同文档,但是依赖文档结构)
替代方法:词词矩阵(Term-Term Matrix):统计词语文本中上下文的频率来理解含义。(有点像qkv?只是最后落到的点不同?)
单词序列模态的语义空间表示(解决上述方法在维度过高的问题):
- 加权平均语义表示向量
- 句子解析树构成矩阵
- 深度学习方法:
- Worf2Vec:训练神经网络分类器预测词的共现(使用上下文窗口来建立每个词的上下文内容,窗口大小确定了上下文范围)
- 输入输出使用的都是独热编码,输入词汇输出每个词汇上下文的概率,使用的是softmax损失函数。维度在100-1000维之间,进行分析时可以使用PCA或者t-SNE这样的降维。
- 缺点很明显:虽然考虑了上下文但是只考虑了出现的概率没考虑具体的语境和句子的实际含义和具体的语序(输入仅仅为单个的词语)
- Glove:将使用的上下文窗口更换为全局的词共现矩阵(整个数据集)
- 词共现矩阵:就是上文说到的词词矩阵但是把视野放到了整个数据集当中,同样没考虑词序的问题(主语谓语宾语)
- Worf2Vec:训练神经网络分类器预测词的共现(使用上下文窗口来建立每个词的上下文内容,窗口大小确定了上下文范围)
视频模态的表示方法
- 不想记录了,截张图吧

多模态表示
一个好的多模态表示应该具有平滑性、时间和空间相干性、稀疏性和自然聚类等特性。
当缺少某些模态数据信息时,依然能产生多模态表示;
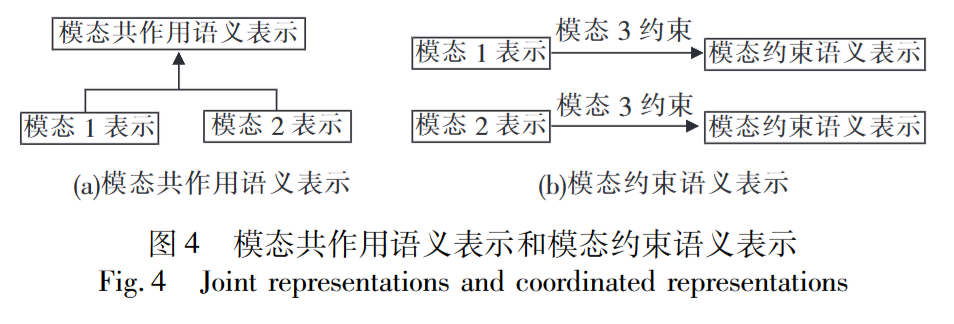
- 模态共同作用语义:融合各模态语义表示。输入为各模态的模态表示然后直接得到预期的输出。
经典结构 编码器-解码器结构:编码器负责共作用语义表示,解码器负责根据共作用语义来表示产生的预测结果。
- 模态约束语义表示:用一个模态的单模态表示结果去约束其他模态的表示,以使其他模态的表示能够包含该模态的语义信息。
模态约束语义表示不同于共作用语义表示,它不是融合各输入的信息并用于完成预测等机器学习任务,而是将输入模态的表示映射到目标模态的语义空间中,使得在目标模态表示空间中,该映射结果与语义相同的目标模态的相似性大于语义不同的目标模态,这个映射结果即为模态约束语义表示。
模态对齐
- 注意力对齐:保证模型的重点是我们想要的区域
- 语义对齐:表示空间里的语义一致性,语义对齐保证“说的是同一件事”。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Blog for AI!
